How We Catch Performance Regressions Before They Hit Production
The Problem
In performance-critical systems, ideally we want to validate every source code change and make sure no performance regressions are introduced. Functional tests handle correctness, but performance is trickier — how do you know a change won't slow things down?
We worked with the OrioleDB maintainers to build a CI pipeline that runs TPC-C benchmarks on every PR and flags regressions before merge.
OrioleDB is a PostgreSQL extension that combines the advantages of both on-disk and in-memory storage engines, using PostgreSQL's pluggable storage to improve performance and reduce costs.
How It Works
Stroppy Action
The best place to detect regressions is where changes are introduced: the Pull Request.
Since OrioleDB lives on GitHub, we built stroppy-action to run Stroppy directly from GitHub Actions:
- name: Run TPC-C benchmark
uses: stroppy-io/stroppy-action@main
with:
preset: tpcc
driver-url: ...
k6-args: ...
stroppy-args: ...
The Pipeline
We created .github/workflows/perf.yml that runs on every PR:
jobs:
setup:
name: Generate run matrix
runs-on: ubuntu-latest
steps:
- id: gen
env:
RUNS: ${{ inputs.bench_runs || '1' }}
WAREHOUSES: ${{ inputs.warehouses || '200' }}
run: |
echo "run-matrix=$(python3 -c "
import json, os
runs = int(os.environ['RUNS'])
whs = [s.strip() for s in os.environ['WAREHOUSES'].split(',')]
print(json.dumps({'run': list(range(1, runs+1)), 'warehouses': whs}))
")" >> $GITHUB_OUTPUT
...
bench-base:
name: "Bench base ${{ matrix.warehouses }}W #${{ matrix.run }}"
needs: setup
runs-on: perf-runner
steps:
- name: Run TPC-C benchmark
uses: stroppy-io/stroppy-action@main
with:
preset: tpcc
driver-url: postgres://${{ env.PGUSER }}@localhost:5432/postgres?sslmode=disable
artifact-name: perf-results-base-${{ matrix.warehouses }}W-${{ matrix.run }}
k6-args: '--out opentelemetry'
stroppy-args: ${{ env.DB_CACHED == 'true' && '--steps workload' || '' }}
...
bench-head:
name: "Bench head ${{ matrix.warehouses }}W #${{ matrix.run }}"
needs: setup
runs-on: perf-runner
steps:
- name: Run TPC-C benchmark
uses: stroppy-io/stroppy-action@main
with:
preset: tpcc
driver-url: postgres://${{ env.PGUSER }}@localhost:5432/postgres?sslmode=disable
artifact-name: perf-results-head-${{ matrix.warehouses }}W-${{ matrix.run }}
k6-args: '--out opentelemetry'
stroppy-args: ${{ env.DB_CACHED == 'true' && '--steps workload' || '' }}
...
compare:
name: Compare results
...
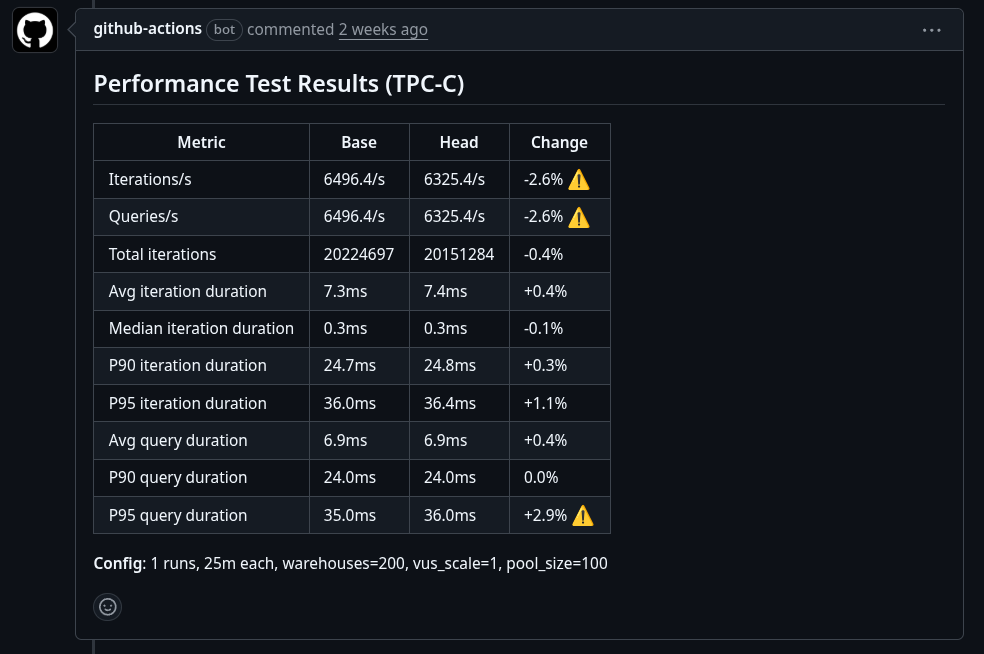
The pipeline benchmarks base and head, compares results, and posts a comment with the outcome.
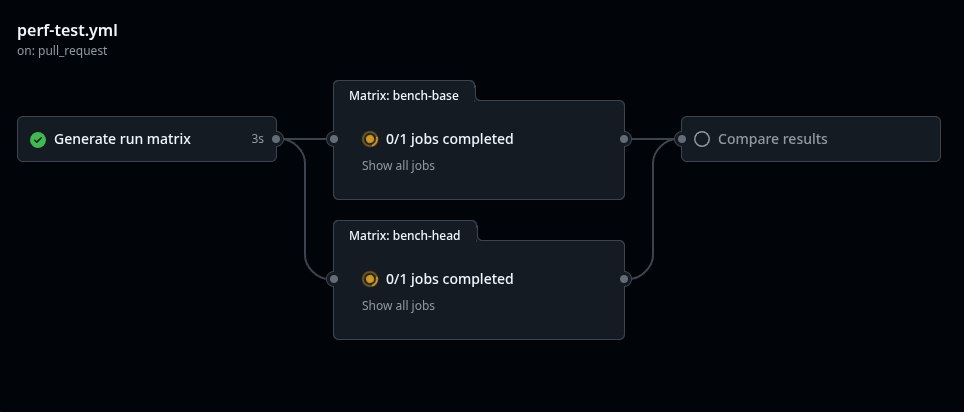
Full source: orioledb/perf-test.yml.
Runners
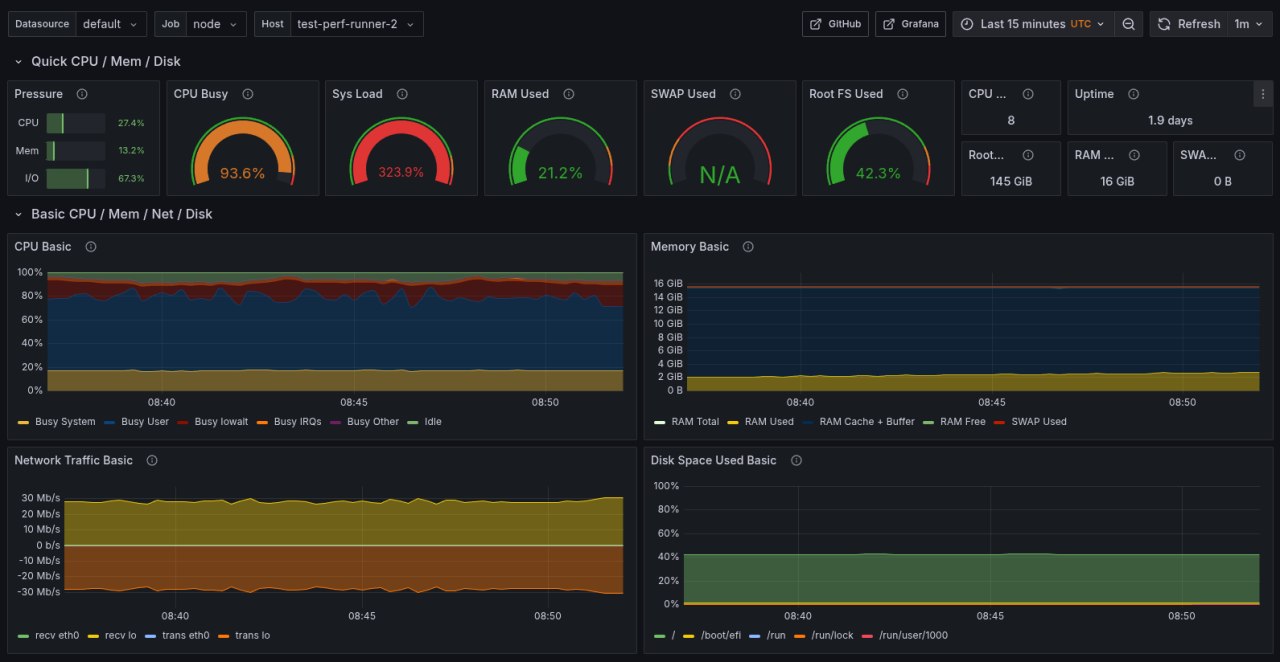
Testing is useless if it's not stable. We use two identical dedicated self-hosted runners to guarantee the same conditions for every run.

Monitoring
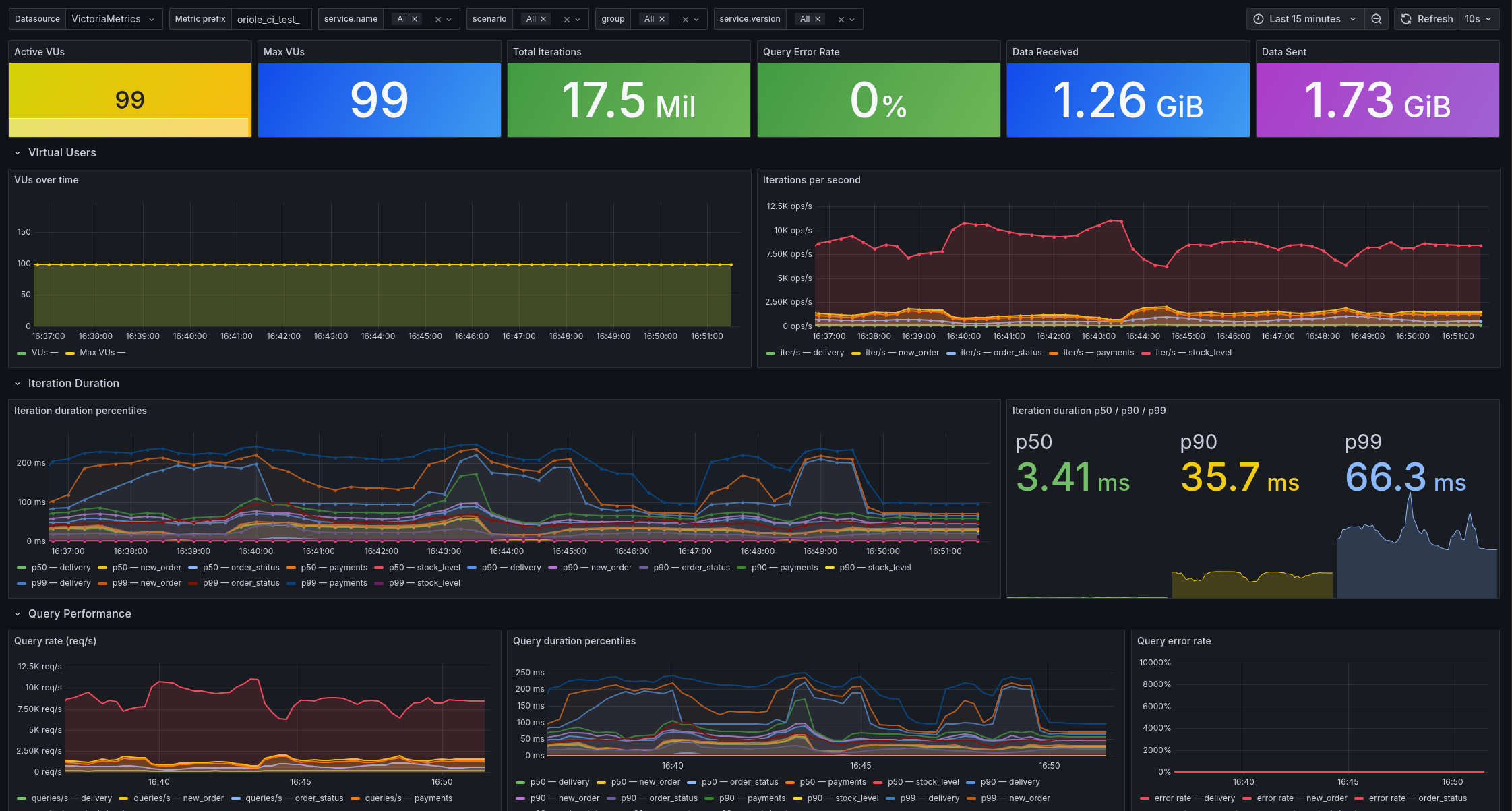
For each runner, we collect everything:
- Full
node_exporterandpostgres_exportermetric sets - K6 and Stroppy metrics via OTEL
- PostgreSQL logs
This lets us see how metrics change during tests and dig into regressions when they happen.
Keeping It Fast
Small datasets don't give you meaningful performance data. We settled on:
- 200 warehouses (~15GB)
- 25 minutes test duration
- 99 virtual users
Loading 200 warehouses takes ~30 minutes, so we cache the data on disk — cuts load time to ~5 minutes. With parallel execution on two machines, the full pipeline runs in ~30 minutes.
Try It Yourself
- orioledb/perf-test.yml — the OrioleDB performance testing workflow
- Stroppy — the benchmark tool, supports multiple databases and workload types
- stroppy-action — GitHub Action for CI integration
- stroppy.io — documentation and guides